
This feature is in preview. This feature is subject to change. To share feedback and/or issues, contact Support.
New in v23.2: You can monitor a physical cluster replication stream using:
SHOW VIRTUAL CLUSTER ... WITH REPLICATION STATUSin the SQL shell.- The Physical Replication dashboard on the DB Console.
- Prometheus and Alertmanager to track and alert on replication metrics.
When you complete a cutover, there will be a gap in the primary cluster's metrics whether you are monitoring via the DB Console or Prometheus.
The standby cluster will also require separate monitoring to ensure observability during the cutover period. You can use the DB console to track the relevant metrics, or you can use a tool like Grafana to create two separate dashboards, one for each cluster, or a single dashboard with data from both clusters.
SQL Shell
In the standby cluster's SQL shell, you can query SHOW VIRTUAL CLUSTER ... WITH REPLICATION STATUS for detail on status and timestamps for planning cutover:
SHOW VIRTUAL CLUSTER application WITH REPLICATION STATUS;
Refer to Responses for a description of each field.
id | name | data_state | service_mode | source_tenant_name | source_cluster_uri | replication_job_id | replicated_time | retained_time | cutover_time
---+--------------------+--------------------+--------------+--------------------+----------------------------------------------------------------------------------------------------------------------+--------------------+-------------------------------+-------------------------------+---------------
3 | application | replicating | none | application | postgresql://{user}:{password}@{hostname}:26257?options=-ccluster%3Dsystem&sslmode=verify-full&sslrootcert=redacted | 899090689449132033 | 2023-09-11 22:29:35.085548+00 | 2023-09-11 16:51:43.612846+00 | NULL
(1 row)
Responses
| Field | Response |
|---|---|
id |
The ID of a virtual cluster. |
name |
The name of the standby (destination) virtual cluster. |
data_state |
The state of the data on a virtual cluster. This can show one of the following: initializing replication, ready, replicating, replication paused, replication pending cutover, replication cutting over, replication error. Refer to Data state for more detail on each response. |
service_mode |
The service mode shows whether a virtual cluster is ready to accept SQL requests. This can show one none or shared. When shared, a virtual cluster's SQL connections will be served by the same nodes that are serving the system virtual cluster. |
source_tenant_name |
The name of the primary (source) virtual cluster. |
source_cluster_uri |
The URI of the primary (source) cluster. The standby cluster connects to the primary cluster using this URI when starting a replication stream. |
replication_job_id |
The ID of the replication job. |
replicated_time |
The latest timestamp at which the standby cluser has consistent data — that is, the latest time you can cut over to. This time advances automatically as long as the replication proceeds without error. replicated_time is updated periodically (every 30s). |
retained_time |
The earliest timestamp at which the standby cluster has consistent data — that is, the earliest time you can cut over to. |
cutover_time |
The time at which the cutover will begin. This can be in the past or the future. Refer to Cut over to a point in time. |
capability_name |
The capability name. |
capability_value |
Whether the capability is enabled for a virtual cluster. |
Data state
| State | Description |
|---|---|
initializing replication |
The replication job is completing the initial scan of data from the primary cluster before it starts replicating data in real time. |
ready |
A virtual cluster's data is ready for use. |
replicating |
The replication job has started and is replicating data. |
replication paused |
The replication job is paused due to an error or a manual request with ALTER VIRTUAL CLUSTER ... PAUSE REPLICATION. |
replication pending cutover |
The replication job is running and the cutover time has been set. Once the the replication reaches the cutover time, the cutover will begin automatically. |
replication cutting over |
The job has started cutting over. The cutover time can no longer be changed. Once cutover is complete, A virtual cluster will be available for use with ALTER VIRTUAL CLUSTER ... START SHARED SERVICE. |
replication error |
An error has occurred. You can find more detail in the error message and the logs. Note: A PCR job will retry for 3 minutes before failing. |
DB Console
You can access the DB Console for your standby cluster at https://{your IP or hostname}:8080/. Select the Metrics page from the left-hand navigation bar, and then select Physical Cluster Replication from the Dashboard dropdown. The user that accesses the DB Console must have admin privileges to view this dashboard.
Use the Graph menu to display metrics for your entire cluster or for a specific node.
To the right of the Graph and Dashboard menus, a time interval selector allows you to filter the view for a predefined or custom time interval. Use the navigation buttons to move to the previous, next, or current time interval. When you select a time interval, the same interval is selected in the SQL Activity pages. However, if you select 10 or 30 minutes, the interval defaults to 1 hour in SQL Activity pages.
When viewing graphs, two perpendicular lines will appear at your mouse cursor providing further insight into the data. The metric values are displayed in the legend under the graph. Click anywhere within the graph to pin the values in place, decoupling the values from your mouse movements. Click anywhere within the graph to cause the values to change with your mouse movements once more.
Hovering your mouse cursor over the graph title will display a tooltip with a description and the metrics used to create the graph.
The Physical Cluster Replication dashboard tracks metrics related to physical cluster replication jobs. This is distinct from the Replication dashboard, which tracks metrics related to how data is replicated across the cluster, e.g., range status, replicas per store, and replica quiescence.
The Physical Cluster Replication dashboard contains graphs for monitoring:
Logical bytes
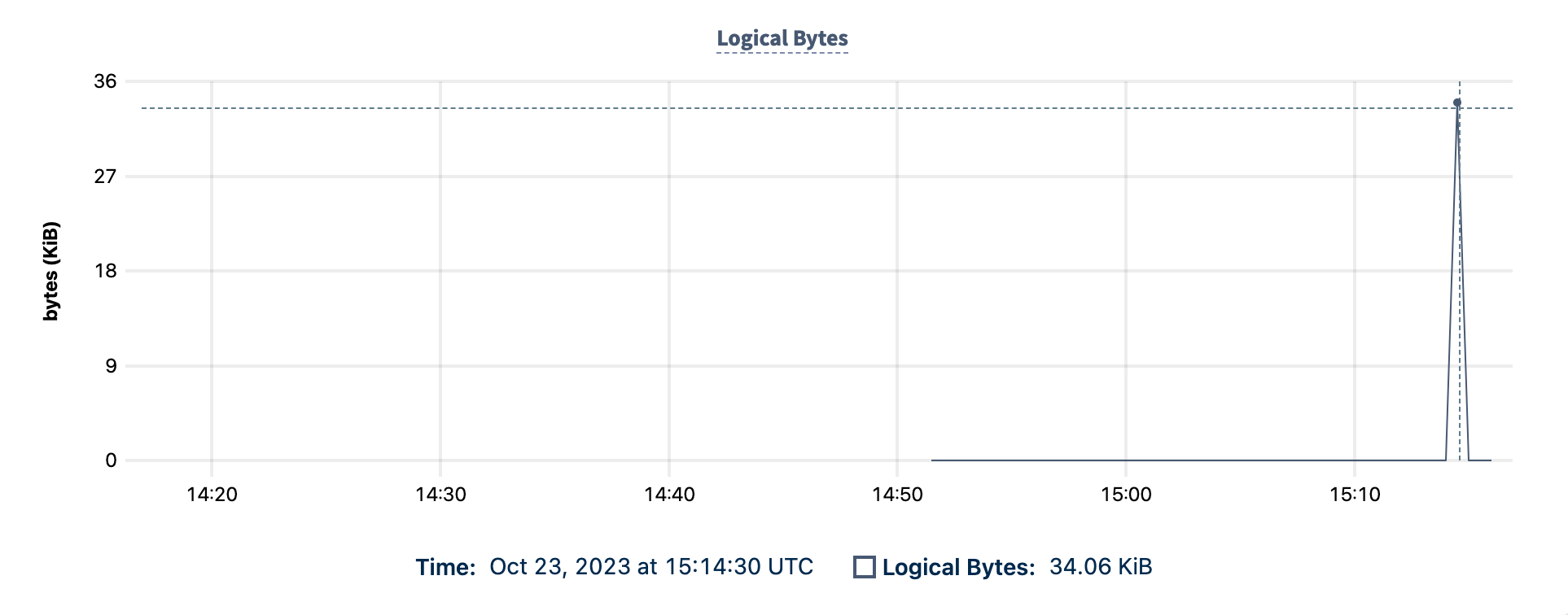
The Logical Bytes graph shows you the throughput of the replicated bytes.
Hovering over the graph displays:
- The date and time.
- The number of logical bytes replicated in MiB.
When you start a replication stream, the Logical Bytes graph will record a spike of throughput as the initial scan completes.
SST bytes
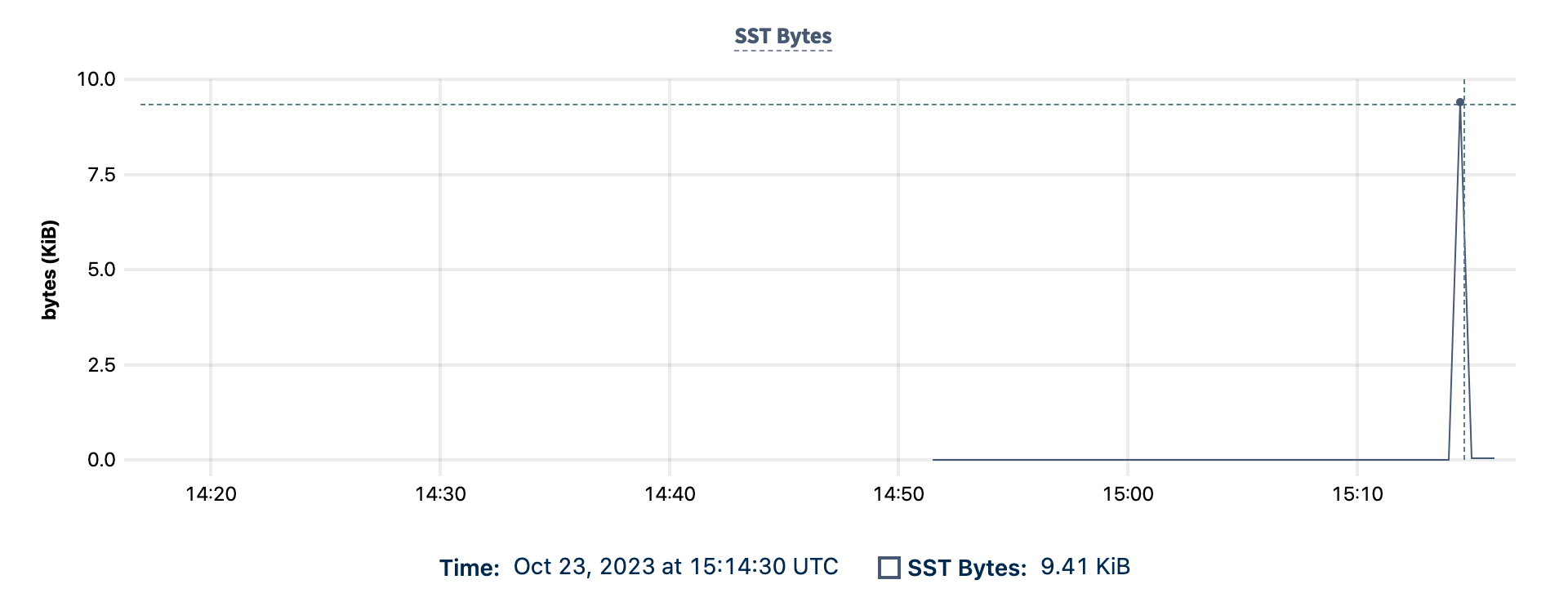
The SST Bytes graph shows you the rate at which all SST bytes are sent to the KV layer by physical cluster replication jobs.
Hovering over the graph displays:
- The date and time.
- The number of SST bytes replicated in MiB.
Prometheus
You can use Prometheus and Alertmanager to track and alert on physical cluster replication metrics. Refer to the Monitor CockroachDB with Prometheus tutorial for steps to set up Prometheus.
We recommend tracking the following metrics:
physical_replication.logical_bytes: The logical bytes (the sum of all keys and values) ingested by all physical cluster replication jobs.physical_replication.sst_bytes: The SST bytes (compressed) sent to the KV layer by all physical cluster replication jobs.physical_replication.replicated_time_seconds: The replicated time of the physical replication stream in seconds since the Unix epoch.
Data verification
This feature is in preview. It is in active development and subject to change.
The SHOW EXPERIMENTAL_FINGERPRINTS statement verifies that the data transmission and ingestion is working as expected while a replication stream is running. Any checksum mismatch likely represents corruption or a bug in CockroachDB. Should you encounter such a mismatch, contact Support.
To verify that the data at a certain point in time is correct on the standby cluster, you can use the current replicated time from the replication job information to run a point-in-time fingerprint on both the primary and standby clusters. This will verify that the transmission and ingestion of the data on the standby cluster, at that point in time, is correct.
Retrieve the current replicated time of the replication job on the standby cluster with
SHOW VIRTUAL CLUSTER:SELECT replicated_time FROM [SHOW VIRTUAL CLUSTER standbyapplication WITH REPLICATION STATUS];replicated_time ---------------------------- 2024-01-09 16:15:45.291575+00 (1 row)For detail on connecting to the standby cluster, refer to Set Up Physical Cluster Replication.
From the primary cluster's system virtual cluster, specify a timestamp at or earlier than the current
replicated_timeto retrieve the fingerprint. This example uses the currentreplicated_time:SELECT * FROM [SHOW EXPERIMENTAL_FINGERPRINTS FROM VIRTUAL CLUSTER application] AS OF SYSTEM TIME '2024-01-09 16:15:45.291575+00';tenant_name | end_ts | fingerprint ------------+--------------------------------+---------------------- application | 1704816945291575000.0000000000 | 2646132238164576487 (1 row)For detail on connecting to the primary cluster, refer to Set Up Physical Cluster Replication.
From the standby cluster's system virtual cluster, specify the same timestamp used on the primary cluster to retrieve the standby cluster's fingerprint:
SELECT * FROM [SHOW EXPERIMENTAL_FINGERPRINTS FROM VIRTUAL CLUSTER standbyapplication] AS OF SYSTEM TIME '2024-01-09 16:15:45.291575+00';tenant_name | end_ts | fingerprint --------------------+--------------------------------+---------------------- standbyapplication | 1704816945291575000.0000000000 | 2646132238164576487 (1 row)Compare the fingerprints of the primary and standby clusters to verify the data. The same value for the fingerprints indicates the data is correct.
See also
- DB Console Overview
- Monitoring and Alerting
- Physical Cluster Replication Overview
- Cluster Virtualization Overview
Was this helpful?